
上一节我们尝试了使用 C++ 来跑相场模拟。除了 C++ 之外,科学计算的另一大热门则是 Python 这门非常火爆的语言。Python 能带给这个模拟什么有趣的特点呢?它的实现可以怎么做呢?一起来看看吧~
为保持系列的统一,头图我们依旧选择了上期出现的,由 Neve_AI 绘制的 AI 爱丽丝。选曲则是最近迷上的,由 塞壬唱片(其实就是鹰角网络)发行的,2025 年夏日活动 《火山旅梦》的主题曲:Misty Memory。这首歌有三个版本:Day version, Night version 和 Instrumental,我们这里放的是 Day version。慵懒的声线非常适合一个人闲暇的时候赏听,希望您能喜欢!
相场法与 Python
说到科学计算,相信绝大多数人都会第一时间想到 Python 这门语言,而事实也的确如此。我们这里依旧简单介绍一下这个语言。
Python:神奇胶水与万能工具
Python 是一门高级程序语言。它诞生于 Guido van Rossem(人称龟叔)在 1980 年代的一个项目,为当时的一个操作系统 Amoeba 制作一款脚本语言,而后被社区大力发展,经历数次变革,最终成为如今的模样。Python 几乎广泛存在于所有的电脑上,就连 GNU 的调试工具 gdb 都会以 Python 作为依赖!许许多多的程序都或多或少地需要一点 Python 的功能,特别是很多计算模拟软件。它的内核可能是用别的语言完成的,但是很有可能它会提供一个定制版的 Python Shell 来方便一些自动化工作,就比如 Abaqus 和 Paraview。
那么,是什么神奇的特性让 Python 有这么广泛的应用呢?这就要提到 Python 这门语言的特性了。
- 首先,Python 的语法规则相对简单:
- 不需要(看起来)繁琐的规则,近乎所见即所得;
- 语法灵活,广泛应用鸭子类型(会叫会跑黄色鸟,那就是鸭子)
- 很多方便有趣的语法特性(List comprehension 等)
- 聪明的解释器可以不需要显式指明类型(即便真的有类型)
- 有很多好用的标准库,使用它们就已经可以做很多事
- 其次,Python 运行在 Python 虚拟机上,在运行时可以逐行解释,方便调试
- 相对应的,很多编译型语言就略显困难,比如 C/C++,需要对编译好的产物使用调试器来 介入 运行中的程序以进行调试
- 不过这里说的是 可以,有一些手段可以近似 编译 Python 脚本来生成运行更快的二进制产物
- 最新的 Python 3.15 版本正在推进 JIT (Just In Time,即时编译),相信它以后会更加好用
- 最后,Python 的成功离不开广大社区的支持
- Python 生态及其丰富,在科学计算领域有许多极为优秀的开源库,如 Numpy,matplotlib,SciPy 等等,提供了许多方便好用的库;
- 除了科学计算,数据分析、统计、机器学习等领域也是极大量地使用 Python 作为基础语言,在它的基础上开发了许多的框架。著名项目 PyTorch 就提供了很不错的 Python 支持。
- 相比于其他的一些语言,Python 的 CUDA 支持更好用,更方便,程序员可以方便地借助显卡的力量进行大规模计算
- 上面的这一切生态离不开社区的友好氛围,以及众多出色的包管理。Python 除了有官方的包管理系统
pip和 PyPI 之外,还有诸如conda这样的优秀包管理/环境管理。它们让配置开发环境变得更简单,更现代。
哦,天哪。Python 竟然如此优秀,也难怪 Python 在众多程序语言排行中屡夺头筹。但是看上面吹得天花乱坠的,这门语言有什么缺点吗?
有的,兄弟,有的。最为人诟病的点大概就是其背靠虚拟机所导致的原生 Python 较差的性能,这也是在 HPC(高性能计算)领域 Python 并不常作为首选的原因。然而,如果我们不用原生 Python,不就好了?简单来说,就是用 Python 作为胶水,把众多实用的工具库 粘 起来,这个粘起来的操作并不会涉及什么高强度的计算,而高强度的计算一般都会放在这些被粘起来的工具里,这些工具则很多是编译好的库,这样一来也能很好地解决性能不足的问题。
为了验证我们的想法,这次我们依旧会用两份代码来说明这个问题,顺便和上次的 C++ 实现做个比较。当然,由于我们用上了 Python 这么好的一款工具,我们的可视化工作就可以直接让 Python 代劳。不过在开始程序编写之前,为了让这个系列不是单调的重复模拟,我们这里再多聊聊相场(灌水
相场与演化方程
尽管相场常用于材料学中的相变模拟,但剥离开其材料学背景,它也不过就是求解依靠某种能量的偏微分方程罢了。我们回忆 Cahn-Hilliard (CH) 方程:
$$ \frac{\partial c_i}{\partial t} = \nabla \cdot M_{ij} \nabla \frac{\delta F}{\delta c_j \left( r,t \right)}; $$按照体系自由能达到全局最小则体系处于热力学最稳定态的理论,如果自由能处于最低点时,自由能泛函对浓度的变分导数 $\delta F/\delta c_j$ 结果应该恒为 $0$ 才对。我们对这一点是有足够的把握的,但为什么能够又基于此构建出这么一个用于演化相场的动力学方程呢?
弛豫假设
这源于一个物理学中的概念:弛豫假设(Relaxation Ansatz)。当我们知道一个体系的平衡态时,我们自然想要知道:一个体系从非平衡态演化到平衡态的过程是什么样的。然而这明显是一个动力学过程,我们必须得到能描述它的演化的动力学方程才可以,即一个含有时间的方程。但是,获得能够准确且完整描述整个体系运动的方程又谈何容易,尤其是当我们只了解这个体系的平衡状态是什么样的时候。
然而好消息是,在绝大多数物理体系中,都有这样的情况:一个体系由某个物理量作为主驱动力,且整个体系的演化速率和这个主驱动力距离平衡态的 “距离” 之间有较简单的联系。对于一个热力学系统而言,它的主驱动力自然是自由能,它与平衡态的 “距离” 可以很好地被变分导数衡量;而体系演化速率和自由能的变化之间有什么联系呢?在众多可能的关系中,成正比 是最简单的那一个。由此我们便得到了 Allen-Cahn (AC) 方程:
$$ \frac{\partial \eta_p}{\partial t} = -L_{pq}\frac{\delta F}{\delta\eta_q\left( r,t \right)}. $$那 CH 方程呢?从形式上看,它的最大特点在于不是直接的正比关系,而是套上了两层 $\nabla$ 的壳。这些壳的出现其实和要演化的变量密切相关:对于保守场,我们需要体系内物质不要随便流出或流入,也就是说该场的散度应该为 $0$。那么从驱动力的角度能怎么实现这个约束呢?我们可以从物质流的角度来看。以浓度这个典型保守场为例,当总物质不增不减时,单位时间内物质的变化必须完全以物质流的形式表现体现出来,即:
$$ \frac{\partial c }{\partial t} + \nabla\cdot \mathbf{J} = 0. $$这个约束保证了,任意某点的浓度变化都会导致产生一个与之抵消影响的物质流。这里的散度正是用来衡量流量大小的工具。因此我们将直接演化浓度的任务划归到了如何演化物质流。而物质流的大小,由经典动力学理论,又是直接与化学势梯度,即 $\nabla (\delta F/ \delta c_j)$,成 正比 的。最后将这一切重新组合起来,就得到了 CH 方程了。
可以看到,在最后的 经典动力学理论 中,我们再一次使用了弛豫假设。事实上,如果考虑到最经典的扩散理论,我们又能随处可见弛豫假设的身影,体系动力学速率总是与某个关键量成正比。
演化方程与相场模型
从某种角度上说,相场的两个经典演化方程是可以这么得到的。查阅一些文献,可以看到由 Ingo Steinbach 等人提出的 多相场模型 就是从平衡态描述出发,辅以弛豫假设,最终得到演化方程的。CH 方程最初可能不是这么简单就获得的(应该是从晶体学的角度,辅以一些扩散理论),但弛豫假设依旧存在于理论的内部。
事实上,就单纯地从动力系统的演化角度而言,有一篇 1977 年的综述文章很好地总结了凝聚态物理中临界态系统的动力学模型:Hohenberg and Halperin: Theory of dynamic critical phenomena,而我们相场中的 AC 方程则对应这篇论文的 System with no conservation laws: Model A,CH 方程则对应了 Conserved order parameter: Model B。很吓人的是,这篇综述里列出的相关模型足足有八大类,相场用到的仅仅是 A 和 B 这两类。不过这两个类别实际上也已经很丰富了,我们实际上可以从这两类模型发展出更多的模型,用来克服各种新的困难,解决新的问题。
然而这里要指出一个点:演化方程不等于相场模型。相场模型严格来讲,是一个用来描述体系的偏微分方程组。这个方程组可以有一个形式化的 演化方程,但是这个形式化的方程还得有能填的进去的 具体能量表达形式。好在,对于相场法而言,能量的选择是较为宽泛的且方便的,因为各类具有物理背景的能量都是可以被直接填进这个能量泛函并发挥作用。因此在程序实现中,我们会考虑将演化方程和能量描述分开来实现,从而结构化地实现相场模拟。
闲谈到此为止,我们开始着手用 Python 进行代码实现吧!
Python 的实现
我们计划在这里使用两种方式来模拟上期中出现的调幅分解。首先我们尝试只是用原生 Python 和其标准库,来看看它的模拟效果如何。第二种方式则是借助一些外部库如 Numpy,观察计算效率有没有变化,并将二者与上期的结果进行比较。
本文中使用的 Python 版本为 3.13.12 (MSC v.1944 64 bit (AMD64) on win 32),由于 Python 解释器的实现在各个平台都是差不多的,我们就不在别的平台试了。
原生 Python
第一版的代码其实说白了就是对之前的 CPP_impl_v1.cpp 直接使用 Python 改写罢了。不过即便如此,这个改写过程也颇为有趣。
首先我们能发现,在 Python 的代码中,在仅依赖标准库的情况下实现我们在 C++ 版本中的功能只很少需要的库,分别是:
- 提供文件夹创建的
os库; - 提供随机数的
random库; - 提供计时器的
time库,
而其余的所有包括数据类型,函数对象等等都是自带的,不需要额外引入库,实在是非常方便(当然,也是有代价的,略显臃肿了)。按照顺序,我们首先考察 write_vtk 函数。
write_vtk 与格式化字符串和循环
1def write_vtk(mesh, folder_path, time_step, Nx, Ny, dx):
2 os.makedirs(folder_path, exist_ok=True)
3 file_name = folder_path + "/step_" + str(time_step) + ".vtk"
4 with open(file_name, "w") as f:
5 f.write(
6 f"""# vtk DataFile Version 3.0
7{file_name}
8ASCII
9DATASET STRUCTURED_GRID
10DIMENSIONS {Nx} {Ny} 1
11POINTS {Nx*Ny*1} float
12"""
13 )
14 for j in range(Ny):
15 for i in range(Nx):
16 f.write(f"{float(i*dx)} {float(j*dx)} {1}\n")
17
18 f.write(
19 f"""POINT_DATA {Nx*Ny*1}
20SCALARS CON float
21LOOKUP_TABLE default
22"""
23 )
24 for j in range(Ny):
25 for i in range(Nx):
26 f.write(f"{mesh[j][i]}\n")
27
28 f.close()
Python 的函数定义只需要 def 关键字和参数列表即可,不需要指明函数的参数类型和返回结果,返回值类型也不需要注明。这正是所谓的自动推导类型系统和鸭子类型的强大所在:用户不需要关心那些可以被推导出的类型,也不需要指明某个参数是什么类型。只要符合在函数体内对这个类型所做出的操作,就可以不考虑其具体是什么。
另外可以观察到,Python 在写文件时使用的是 open 函数,以后面的字符串代表打开文件的类型(是读还是写),最后 with open() as f 来给打开的内容以名称。这样的写法非常贴合英语的阅读语序,这也是 Python 受大家喜欢的一个原因。另外,这样的做法也保证了只有在文件对象 f 被打开时执行内部操作,而当文件关闭时则立刻停止执行。而写入的内容中,出现了这样的内容:
1f"""# vtk DataFile Version 3.0
2{file_name}
3ASCII
4DATASET STRUCTURED_GRID
5DIMENSIONS {Nx} {Ny} 1
6POINTS {Nx*Ny*1} float
7"""
这是所谓的格式化字符串 f-string 以及 docstring 的结合产物,它可以在 """ 内按字面意思存储字符串的格式信息,在这种情况下颇为好用,避免了我们在 C++ 实现中用流式输出一点点将变量和字符串混输的丑态。
在这个函数中,还有个有趣的点在于 Python 的循环。在 Python 中,所有的 for 循环都通过迭代产生,因此当我们使用 for 循环时,必须有一个可供迭代的容器式的对象,而为了从 0 循环到 N-1,Python 提供了 range() 对象来解决这个问题。当使用 range(N) 时,它就自动创建了一个可遍历的迭代对象,依次从中取出 0,1,一直到 N-1。某种程度上,这种做法更加明确地区分了 for 循环和 while/do while 循环,让 for 循环看上去不再只是 while 循环的简写。
mesh_periodic 与 Python 的变量
接下来的 mesh_periodic 函数再次体现了 Python 鸭子类型的优势:
1def mesh_periodic(mesh, Nx, Ny, dx, ker_func):
2 new_mesh = [[0.0] * Nx for _ in range(Ny)]
3 # new_mesh = [[0.0] * Nx] * Ny
4 for j in range(Ny):
5 for i in range(Nx):
6 v_c = mesh[j][i]
7 v_l = mesh[j][i - 1] if i != 0 else mesh[j][-1]
8 v_r = mesh[j][i + 1] if i != Nx - 1 else mesh[j][0]
9 v_d = mesh[j - 1][i] if j != 0 else mesh[-1][i]
10 v_u = mesh[j + 1][i] if j != Ny - 1 else mesh[0][i]
11 new_mesh[j][i] = ker_func(v_c, v_l, v_r, v_u, v_d, dx)
12
13 return new_mesh
这里我们的函数参数不需要将类型明确写出,从而省去了用又臭又长的类型说明 ker_func 是某个明确的函数对象。另外,在创建临时网格的时候,也许您会注意到这里我们有两种写法:
1new_mesh = [[0.0] * Nx for _ in range(Ny)]
2# new_mesh = [[0.0] * Nx] * Ny
在 Python 中,让一个 list 乘以一个整数的含义是让这个 list 中的数值重复整数倍,因此 [0.0] * Nx 的意思是创建一个长为 Nx 的,填满 0.0 的列表;而 [xxx for _ in range(Ny)] 则是 Python 的一个语言特性,名为 List comprehension(我想不到怎么翻译它 so bear with me pls)。它的作用是直接通过后面的表达式来填充列表,有点像是在原地生成列表中的元素,生成规则则写在 [] 里面。这里的这段意思就是将 [0.0] * Nx 这个作为一个代表元,生成 Ny 次。如此,我们便得到了这样一个列表,它的里面有 Ny 个元素,每个元素都是一个装着 Nx 个 0.0 的列表。
但是既然如此,为什么不用 [[0.0] * Nx] * Ny 呢?我们来做个小实验。打开一个命令行,输入 python 后进入交互式环境,然后逐行输入下面的内容:
1a = [[0.0]*2]*5
2a
3a[0][0] += 1.0
4a
小朋友,你是否有很多问号()我们再试试这个:
1b = [0.0]*2
2c = [b]*5
3c[0][0] += 1.0
4b
看到这个结果,也许你已经猜到是怎么回事了。上下两种写法在 Python 看来是一样的,即我们是从 c 这个保存了 b 的 引用 的列表中取出了某一个单独的引用 b,然后让对引用中的第一个元素加上了 1.0。因为 c 中存储的每个内容都是引用,对引用的变动会直接反映到变量自身,因此自然地, c 的每个元素的第一位(也就是 b 的第一位)就成为了 1.0。或者说,如果采用 new_mesh = [[0.0] * Nx] * Ny 的写法,我们并不是真的得到了 Nx * Ny 个 0.0,而是得到了 [0.0] * Nx 这个对象的 Ny 个引用。
为什么会这样?为什么 b = [0.0] * 3 在 b[0] += 1.0 的时候不会得到 [1.0, 1.0, 1.0],而 c[0][0] += 1.0 会让列表的每个元素第一位都加 1?这涉及到 Python 独特的变量管理策略。Python 的变量 不一定 是个像其他语言那样的单纯的,用来装一些数值的 “盒子”。有一部分的 Python 对象被划分为 可变的(mutable),而其余的部分为 不可变的(immutable)。(一部分)整数,(一部分)字符串和一些数据结构是不可变的,如果 “存储” 它们的变量的值发生变化,那么将会创建一个新的对象来重新绑定到变量上,而不是直接操作到这些不可变的值上;相对应的,对那些可变的对象,引起它们变化的操作一般不会创建新的对象,而是在原对象上直接做变化。所以,对 Python 而言,对象是被绑定在变量名上的,而对变量名的操作其实都是在尝试对它们绑定上的值(对象)进行操作,再根据对象的类型决定是要重新绑定还是变化原有的对象。
那么这些区别对 b 和 c 有什么影响呢?实际上这要再谈到 expr * N 这一操作的作用。在对列表用 * N 时,它会尝试对前面的表达式进行 一次计算,然后尝试把这个结果的引用绑定在列表的 N 个位置上。对于不可变对象而言,当对其中某个位置的不可变对象进行操作时,因为它 不可变,让这个位置发生变化的唯一方式是重新构造符合要求的对象;对于可变对象而言,由于每个位置绑定的都是前面计算出的 唯一的结果 的引用,对某个位置的变化会直接改变这个 唯一结果 的值(因为它可变),而 * N 只会复制引用,不会拷贝值,所以这个位置的变化会反映到这个列表中的所有位置。
而 [[0.0] * Nx for _ in range(Ny)] 能实现我们需求的原因,也不过是 for 循环中会老实地把这个对象创建 Ny 次然后塞进这个列表中,其中每个长为 Nx 的列表都是相互独立的。我们绕了一大堆,希望您能理解 [[0.0] * Nx] * Ny 发生了什么,以及为什么需要改这个写法。这个问题困扰了笔者一段时间,最后也是在 Stack Overflow 以及 AI 的帮助下才解决了。令人惊喜的是,Python 官方文档的 Q&A 中就收录了 这个问题,感兴趣的可以看看。
循环内部的操作其实很简单,不过是我们把条件判断写成了单行的形式,看起来更加 fancy 罢了。不过这种 expression1 if condition else expression2 的写法也是经过了若干次讨论之后,在 PEP 308 才敲定的,背后也有一些故事,我们这里就不再展开了。最后我们没有使用 Nx - 1 而是直接使用 -1 来取列表中的最后一个元素,这也是 Python 为我们提供的一些便利之处了。最后我们直接让 ker_func 按顺序吃满 6 个参数后把结果绑定在 new_mesh 的第 j 行第 i 列,就完成了一个点的计算。
main 函数与主循环
我们知道 Python 作为一门解释型语言,是不需要 main() 函数来作为程序入口的。然而这里我们依旧使用了 main。这也是为了体现 Python 的另一个特点,“文件即模块”。Python 会把每个脚本都当作模块,并给它们提供了几个变量作为模块的元信息。比如该实现最后用到的 __name__ 和 __main__。如果源代码被直接运行了,那么 __name__ 这个变量就会被赋值为 __main__,这也是我们最后写 if __name__ == "__main__" 的原因。当然,由于我们的实现里并没有别的文件/模块,实际上直接写 main() 的效果是一样的。这些特殊变量被称为 magic attributes,魔术属性,而这个双下划线也有对应的英文,名为 dunder,取 Double-Underscore 之意。
让我们进入主循环,为了计时,我们使用 time 模块提供的 perf_counter 函数,它能提供高精度的计时时点。随后便是要给后续模拟中使用的参数赋值。在 Python 中,人们常用全大写的变量名来代表这是一个常量,但是由于 Python 没有强制性的常量,全大写仅仅是一种命名规范,并不是规则。另外,为了能让我们方便地批量定义变量,我们这里使用了 元组展开 的写法,把要用到的参数写在一个元组中,然后用对应数量的变量名去 “接住” 元组中的结果,避免我们有多少变量就要写多少行代码的窘境。
1start = time.perf_counter()
2Nx, Ny, Nstep = (64, 64, 10000)
3dx, dt = (1.0, 0.01)
4kappa, M, A = (0.5, 1.0, 1.0)
5dcon, con_init = (0.05, 0.4)
在初始化结构这里,我们模仿之前在 C++ 实现中的写法,在用初始值填充好列表之后,用 random 这个库提供的 uniform 函数来方便地给出范围内的随机数,并赋给对应的点。
1con_mesh = [[con_init] * Nx for _ in range(Ny)]
2for j in range(Ny):
3 for i in range(Nx):
4 con_mesh[j][i] += random.uniform(-dcon, dcon)
接下来我们提前准备好后面要用到的计算内核。这里依旧采用 Lambda 表达式,不过相比 C++ 的定义方式,Python 中要求使用 lambda 关键字来定义 Lambda 表达式。另外,Python 的 Lambda 表达式默认会捕捉可捕捉的所有变量,不需要像 C++ 那样明确要捕捉的变量。在 lambda 关键字后写好所有的变量并以冒号分割参数与返回值,lambda 表达式就写好了。
1df_dc_ker = lambda v_c, v_l, v_r, v_u, v_d, dx: df_bulk_dc(
2 v_c, A
3) - kappa * laplacian(v_c, v_l, v_r, v_u, v_d, dx)
不过要注意的是,lambda 表达式的作用在于提供一个快速的,可抛弃的表达式,这里这个表达式实际上会被使用多次,且我们还给它明确定义了一个名字。根据 PEP 8,在这种情况下我们最好使用 def 关键字定义一个函数对象:
1# def df_dc_ker(v_c, v_l, v_r, v_u, v_d, dx):
2# return df_bulk_dc(v_c, A) - kappa * laplacian(v_c, v_l, v_r, v_u, v_d, dx)
由于 def 关键字实际上定义的其实是函数对象,我们不需要专门把它拉到 main() 函数前面再定义,而是可以直接原地定义好它。
接下来便是循环迭代,将结果通过 write_vtk() 函数写入文件,并统计时间:
1for istep in range(Nstep + 1):
2 df_dc = mesh_periodic(con_mesh, Nx, Ny, dx, df_dc_ker)
3 dc = mesh_periodic(df_dc, Nx, Ny, dx, laplacian)
4 for j in range(Ny):
5 for i in range(Nx):
6 con_mesh[j][i] += dt * M * dc[j][i]
7
8 if istep % 100 == 0:
9 write_vtk(con_mesh, "./output", istep, Nx, Ny, dx)
10 print(f"Result {istep} outputed")
11
12end = time.perf_counter()
13print(f"Elapsed: {(end-start):.3f} seconds.")
这里值得注意的是 print 函数。在 Python 中,我们终于有了一个十分好用的 print 函数,配合上格式化字符串来直接将结果方便地输出到控制台,而且它还会自动换行。当然,如果我们不希望它换行,我们可以指定 end 参数来改变打印结束后的末尾应该打印什么。它的默认值是 "\n",即换行符。
至此,我们成功地使用 Python 完整实现了调幅分解。这一版的代码可以点击 这个链接 来浏览和下载。运行结果显示,在输出结果到文件的情况下需要约 19.7 秒完成计算,而在不将结果输出到文件的情况下,完成计算也需要大约 19.3 秒。这说明这个版本的 Python 程序完全不是因为文件 IO 而效率低,单纯是因为计算太慢。对比 C++ 的结果(详见上期评论区),当我们选择输出到文件时 5000 步耗时约 2.4 秒(10 000 步消耗约为 4.9 秒),而当不需要输出到文件时 5000 步需要耗时 0.29 秒(10 000 步消耗约为 0.5 秒)。
那么,这份代码有没有什么可以优化的呢?使用 Numpy 等经典第三方库能帮助我们更快的计算吗?
Python with Numpy
我们直接上手试一试!笔者安装的 Numpy 版本为 2.4.4,我们选择在使用 pip install numpy 安装好 numpy 后,单纯地用 numpy 的 numpy.array 来替换我们的网格,即:
1# new_mesh = [[0.0] * Nx for _ in range(Ny)]
2new_mesh = np.array([[0.0] * Nx for _ in range(Ny)])
顺带地我们可以像矩阵数乘和矩阵加法那样直接将计算得到的 dc 更新到 con_mesh 上:
1con_mesh += dt * M * dc
2# for j in range(Ny):
3# for i in range(Nx):
4# con_mesh[j][i] = dt * M * dc[j][i]
结果如何呢?肉眼可见的慢!本来只需要不到 20 秒的计算,现在竟然用了 87 秒才完成…… 是哪里出问题了吗?
啊,一定是因为我们没有在 np.array 里直接更新,而是重新创建新的变量的缘故!我们做一些修改,让 mesh_periodic 不再创建新的临时对象,而是直接将结果更新到参数列表中传入的变量里,然后在时间循环开始前就创建两个临时变量来承载待会儿要更新出的变量:
1def mesh_periodic_update(mesh, updated_mesh, Nx, Ny, dx, ker_func):
2 for j in range(Ny):
3 for i in range(Nx):
4 v_c = mesh[j][i]
5 v_l = mesh[j][i - 1] if i != 0 else mesh[j][-1]
6 v_r = mesh[j][i + 1] if i != Nx - 1 else mesh[j][0]
7 v_d = mesh[j - 1][i] if j != 0 else mesh[-1][i]
8 v_u = mesh[j + 1][i] if j != Ny - 1 else mesh[0][i]
9 updated_mesh[j][i] = ker_func(v_c, v_l, v_r, v_u, v_d, dx)
10
11# ...
12
13def main():
14 # ...
15 con_mesh = np.array([[con_init] * Nx for _ in range(Ny)])
16 df_dc = con_mesh.copy()
17 dc = con_mesh.copy()
18 # ...
另外我们顺带把 Lambda 表达式换成用 def 关键字定义的函数:
1def df_dc_ker(v_c, v_l, v_r, v_u, v_d, dx):
2 return df_bulk_dc(v_c, A) - kappa * laplacian(v_c, v_l, v_r, v_u, v_d, dx)
再试试!……不行。运行的那一瞬间就知道不对。每百步的输出一下一下地蹦出来,怎么看都不是很快的样子……还有什么,还有什么可以优化的地方?
对了!要不要把 df_dc_ker 拆开?这样的计算核反而是没有能借助 Numpy 的批量计算功能。试试看:
1# mesh_periodic_update(con_mesh, df_dc, Nx, Ny, dx, df_dc_ker)
2mesh_periodic_update(con_mesh, df_dc, Nx, Ny, dx, laplacian)
3df_dc = df_bulk_dc(con_mesh, A) - kappa * df_dc
如何?这次会不会快很多?别急,我们想到计算除法总是比计算乘法复杂一些,而除法在我们的代码里几乎只用在 Laplacian 计算过程中。我们完全可以提前计算好 $\frac{1}{\mathrm{d} x ^2}$ 然后再在后面直接乘上去。我们记这个新算法为 laplacian_inv_dx2:
1def laplacian_inv_dx2(v_c, v_l, v_r, v_u, v_d, inv_dx2):
2 return ((v_l + v_r + v_u + v_d) - 4 * v_c) * inv_dx2
3# ...
4dx, dt = (1.0, 0.01)
5inv_dx2 = 1/(dx * dx)
6# ...
这次再试试。结果很棒!我们成功地降低了 10 秒!
唉简直就是小丑……说好的 Numpy 很快呢?怎么用上 Numpy 之后反而变慢了!??!不论如何,完整代码奉上:PY_impl_v2.py,欢迎阅读/下载/嘲笑()
Numpy 的真正实力!
既然已经成了小丑,问问 AI 又能怎么样?问!
这不问不知道,一问才明白,慢出来的时间主要全都消耗在 Python 和 Numpy 的 界面 上了。什么意思呢?本来我们如果用 Python 的原生列表,那就老老实实计算就完事儿了,速度比 C++ 慢是可以理解的,毕竟 Python 作为一门解释型语言,它的循环效率低于 C++ 也不奇怪。但是当我们把原生列表换成 Numpy 的 np.array 之后,事情就变了。
Numpy 的 np.array 在创建时,实际上会创建一个类 C 语言数组那样的结构出来。而 Numpy 这个数学库高效的主要原因就在于它使用了许多前人总结的算法与好用的数据结构,就比如这里被包装起来的 np.array。可是坏消息是:我们并没有真正运用这个数据结构的方法,而是单纯拙劣地把它搬了出来,然后用了一下它的矩阵数乘和加法,仅此而已。而最消耗计算资源的 Laplacian 计算这里,我们依旧是用传统的手工活儿来执行。
不,这甚至更糟糕:我们在对 con_mesh 这个 np.array 求 Laplacian 的时候,需要取某个位置的前后左右四个值还有中心的值。在取值的时候我们用了 [] 下标运算符来处理,而这反而进一步增加了计算消耗。我们用一个 Python 的写法告诉让 Numpy 让它从一个数组中的某个位置取出一个值,这个近乎翻译的过程,一次的时间消耗也许并不明显,但在进行 $64\times 64\times 5 \times 2 \times 10 000= 409 600 000$ 次调用之后,再怎么快的调用也会露出鸡脚的。另外,我们的算法完全没有发挥出 Numpy 的巨大优势:向量化。如果所有的数据组都能被批量,一次性地同时处理,而不是老老实实地一个个循环走过去,那计算效率肯定会发生质的提升!
所以我们到底要怎么做,才能发挥 Numpy 的真正实力呢?鉴于我们的模拟使用的是周期性边界条件,而 Numpy 正好有个函数 np.roll 能够 转动 被操作的网格从而方便我们计算 Laplacian,我们这里就借助它的力量,定义一个新的函数 laplacian_np:
1def laplacian_np(mesh, inv_dx2):
2 return (
3 np.roll(mesh, 1, axis=1) # left
4 + np.roll(mesh, -1, axis=1) # right
5 + np.roll(mesh, 1, axis=0) # down
6 + np.roll(mesh, -1, axis=0) # up
7 - 4 * mesh
8 ) * inv_dx2
这个函数不是逐点计算得到每个点的 Laplacian 值的,而是一次性将整个网格的 Laplacian 计算出来,因此避免了 Python 的循环操作。我们用这个函数来实现时间循环中的计算步骤:
1for istep in range(Nstep + 1):
2
3 lap_c = laplacian_np(con_mesh, inv_dx2)
4 df_dc = df_bulk_dc(con_mesh, A) - kappa * lap_c
5 dc = laplacian_np(df_dc, inv_dx2)
6 con_mesh += dt * M * dc
7 # ...
这次需要跑多久呢?10 000 步的计算(包括文件输出)总共用时为:1.15 秒!这甚至比我们之前的 C++ 实现还要快上很多!而当我们不选择输出到文件中时,结果约为 0.52 秒,与 C++ 的结果相当。
所以,为什么会快这么多?一个关键点在于:我们不再需要让数据频繁跨越 Python 与 Numpy 之间的屏障,另外就是我们不再依赖 Python 的低效循环了,而是使用 Numpy 提供的高效数据结构自身的循环。
你也许会问:不过是不用 Python 自己的循环了,让 Numpy 负责结构的内部循环怎么能快这么多?其实关键点在于,CPU 执行的时候也许也不是老老实实循环了,而是采用了 向量化 技术,对这里的 $64\times 64$ 的数据 直接加减乘除,也就是说相比于老老实实循环,保守估计能快个 400 倍。实际上,向量化技术是现代 CPU 计算的重要技术,也是 HPC(高性能计算)的重点优化方向。如果一个计算过程能够被向量化,那么这个计算的速度就能得到极大的提升。
另外就是内存是否能被迅速地加载进 CPU 核心中进行计算。现代计算机技术已经相当发达,加减乘除取模运算这些早就已经被优化到只需要若干时钟轮就能得到结果了,但是从内存中找到需要计算的对象却依旧相对较慢。为了解决这个问题,人们设计了 CPU 的多级缓存,如果计算数据能够被一次性加载到最快(同时也最小)的 L1d 缓存中的话,那计算速度会相当快(因为真的只需要算就好,不怎么需要寻找数据,也就是不怎么发生 cache miss,缓存未命中)。要是数据太多,那如果能被放在稍慢的 L2 中的话,那也不会好几次都没命中缓存;要是数据再大一些,或者计算流程设计的不好,那可能 CPU 没能把数据很好地加载到这两个位置,那计算可能就会很慢了。
一般来说现代 CPU 都有 L1, L2, L3 三级缓存,其中 L1d 是给数据留下的空间,L2 和 L3 基本都归数据;想要查看自己 CPU 的各级缓存大小,Linux 用户可以使用 lscpu 命令,Windows 用户…… 我用 WSL()下面是我用 WSL 中的 lscpu 帮我列出的我这本笔记本的 CPU 情况:
1Caches (sum of all):
2 L1d: 768 KiB (16 instances)
3 L1i: 512 KiB (16 instances)
4 L2: 16 MiB (16 instances)
5 L3: 32 MiB (1 instance)
我的 L1d 缓存有足足 768 KiB!而 $64\times 64$ 的网格数据如果全都存储 double 类型数据,若 double 类型数据大小为 64 比特 8 位,那这个网格占用的内存则为 32 KiB,完全可以放的进 L1d 缓存中。这也是为什么在用上 Numpy 的数组之后 在使用内部循环的条件下 计算如此之快的原因了。
同样地,我们把代码贴在 这里,欢迎查阅、下载和取用~。
其他的开源库呢?
除了 Numpy 以外,实际上 Python 可用的开源库相当庞大。我们这里再给最后一版的程序加一些内容,以其展示 Python 的更多语言特性。就比如几乎与 Numpy 形影不离的 matplotlib 以及图形界面领域的老资历 Qt 的 Python 实现 PyQt6。
最后一版的代码我们尝试进一步模块化,毕竟 Python 算是笔者熟悉的语言中最好搞花活儿的了,而模块化也许就算是笔者了解的花活儿之一吧。
首先我们规定两个大类,一个用来存储我们的数据网格 Mesh,另一个则是专为本次模拟服务的 Solver_CahnHilliard 求解器(下简称为 Solver)。在数据网格中我们 只 记录与网格有关的所有信息,而在求解器中我们则 只 记录与求解有关的所有信息。
因此,在 Mesh 类中,我们主要关心这些事:网格的大小,步长,该网格存储的数据,以及对这个网格的一些初始操作,比如赋值,创建,添加噪声,计算 Laplacian(这也许不是个好主意,但是我放在了这里,因为它和网格强相关)。而在 Solver 中,我们关心的则是:求解总步数,输出步数,时间步长,被求解网格,求解器相关参数,能量的偏导形式,而对这些数据的操作则可以简单概括为时间循环与结果输出。
在定义好这两个类之后,我们要做的就很简单了:直接创建好网格,然后初始化求解器,最后求解,启动!就可以得到结果了。因为我们的案例实际上网格很小,完全可以被塞进内存里,因此我们可以在跑完所有结果之后根据需要来输出到文本中,或者借助 matplotlib + PyQt6 的力量,直接打开一个图形化窗口来观察结果:
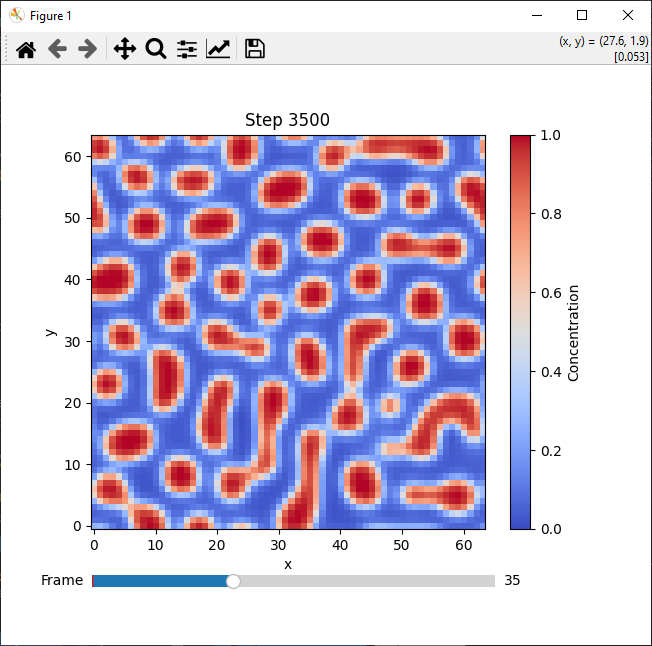
这份代码实际上还有很多可以优化之处,比如 “求解器” 究竟应不应该在内部定义主循环?如果要耦合多种能量的话,是不是最好把能量贡献放进一个 List 中然后遍历调用?是否应该将一些自由能的偏导形式内置在 Cahn-Hilliard 求解器的内部?
然而这些问题我们暂时都不再深入考虑了。这份代码的具体内容放在 这里,欢迎下载运行尝试!注意要安装 numpy,matplotlib 和 pyqt6 三个库哦~关于运行效率问题,我的机器上完成模拟需要约 1.6 秒,这比我们之前的实现结果要差了不少,但是它的优点在于能炫技以及提前优化,也就是没有优点。不过如果你认为这份代码能帮你了解 Python 的别的语言特性,那即便它没有优点,也是有意义的()
总结与后记
Python 比我想象的要难很多。作为一门 “工具语言”,我实际上对 Python 的了解并不多,很多东西写的时候都是网上现查的(当然也离不开 AI 的帮助)。我希望通过从代码结构,书写方式,运行效率等角度,把这里的四个案例和上一次的 C++ 两份代码做一些对比,来说明这样一个问题:代码的运行效率,归根结底还是落在 程序员能否写出高效的程序,而不是 语言是否高效。一门语言它也许本身比较慢,但这样的代价一定是换来了一些更好的结果的,而在 Python 这里,换来的是极强的易用性,以及甚至由于易用性而发展出来的庞大的用户群。我相信,也正是因为这庞大的用户群,让 Numpy,SciPy,matplotlib 等开源库愿意不断向社区做贡献,让这门语言的生态如此丰富。
然而,一门语言自身是否 “高效”,到底还是会影响人们在处理某些事务的时候首选的语言。比如 Python,很多人诟病的点就在于速度。然而如果我们使用上 Numpy 的数组 外加一些对库的了解,就能写出完全不输于 C/C++ 这类通常被认为 “更接近底层”,“更有效率” 的语言。事实上,Numpy 高效的关键点在于它其实是编译出的,可供 Python 调用的二进制库,而在库中它使用了比如 BLAS 这类的专业数学处理工具库,因而相当于提前预料到用户的使用行为,从而更好地优化数据的计算过程。
这样的预编译二进制操作不仅适用于 Numpy 这类计算库,同时也适用于很多机器学习库/框架。这也是为什么大家愿意用 Python:在合理使用库函数的前提下,既能保证效率,又能快速验证/实现自己的想法。这也正是 Python 这门语言最响亮的招牌:Life is short, I use Python!(人生苦短,我用 Python!)
那么就是这样!希望您喜欢这次的内容。由于可爱群友 開源 lib( 以迅雷不及掩耳盗铃儿响叮当之势为我的博客装载了 React 和 TailwindCSS 这些现代前端套件,我觉得没有理由把 JavaScript 版本的实现再向后推迟。本系列的下一期我们将尝试使用 JavaScript 实现调幅分解,同时也是给笔者一个机会来学习一下最新最潮流的 JavaScript~ 最后,感谢您的阅读,祝您身心健康,happy coding!~