
目前做相场的大家似乎都在用 C++ 或者 Python 来跑相场,可是明明程序语言这么多……对吧?Why not?本系列就来整个小活儿,用各种各样的语言来实现某个相场模拟~ 不过千里之行始于足下,我们就从最常用的 C++ 开始吧!~
头图依旧是 Neve_AI 绘制的 AI 爱丽丝,可爱捏~ 我似乎越来越喜欢 AI 图了。选曲则是最近我很喜欢的 Duvet,它是动画《玲音》的主题曲,有点凄美的感觉,非常抓耳……分享给要看这篇充斥着程序计算的你~(依旧图曲文无关)
可恶的wyy怎么要会员呜呜呜,不过 B 站也可以直接听:「玲音」主题曲 Duvet
缘起:模拟与程序语言
某个阳光明媚的下午,一切都是那么的惬意,亲爱的群友 開源 lib( 分享了他的最新选题:在浏览器中做个示波器(详见:【無線測距系統/下】AirTag 的物理碾壓和藍牙 6.0 的發力)!而且他也建议我可以把一些东西交互式地搬上浏览器,搬进博客里。
我必须说:非常好提议,但是 HOW?要搬进浏览器,那怕不是要用 Javascript,但是 JS 又要怎么跑相场呢?跑出来的结果又要怎么办呢?一般来讲,相场跑出来的结果都会用 VTS 格式存储为一系列的文件,然后再用 Paraview 来可视化这些结果。那如果在浏览器里的话……想不到什么好办法。
不过,这个点子狠狠地启发了我!虽然浏览器上做这些确实可能有点难,再加上我不太懂 JS/TS(本博客的程序部分 vibe 成分极高),用浏览器跑相场这事儿目前确实是有点难度了;但是,为什么我们总是选择用 C++ 和 Python 来做模拟呢?诚然,对 性能 的追求是很现实的需要,但是我们也可以试试用别的程序语言来实现模拟呀?说到底,相场模拟也不过是做一些数值计算嘛。
所以,我们就从笔者最熟悉(也许)的 C++ 开始,试试用更多的程序语言实现相场模拟吧!
相场模拟简介
不过,在实现相场模拟之前,你也许会问:什么是相场?
简单来说,材料中有很多的相,做实验之后能看到材料的相结构,但是如果不用非常非常贵的原位实验手段的话,是很难看到相变进行的过程的。而相场法就是一个通过数值计算来模拟相变过程的计算方法。在模拟中,我们会划定一个小区域,在里面使用 $1$ 代表某个区域完全被某个相占据,$0$ 代表某个区域里完全没有这个相,而 $0$ 到 $1$ 之间的值就说明是在相边界的位置。驱动相场演化的主要因素是这个系统的能量,绝大部分情况都是由两个大块儿组成:体能和界面能。体能负责让相与相从混乱的状态不断分离,让体系完全变成热力学所描述的样子;界面能则起到相反的作用,它会帮助界面的生成,让相与相之间有一个 扩散 的界面,或者说让取值在 $0$ 到 $1$ 之间的区域变多一些。合理调配这两种对抗的能量贡献,就能让相场不断演化下去。
而实际的演化过程则是由偏微分方程控制。根据变量的特点,我们会用两大类方程来推进相场演化:当变量是保守的,即这个变量在模拟区域的总量应该是固定不变的的时候,我们就用 Cahn-Hilliard 系列的方程来演化,最经典的就如浓度场;而当变量没有保守条件,我们则会用 Allen-Cahn 系列方程来演化这个场。两个方程都有个最基础的形式,其中 Cahn-Hilliard (CH) 方程为:
$$ \frac{\partial c_i}{\partial t} = \nabla \cdot M_{ij} \nabla \frac{\delta F}{\delta c_j \left( r,t \right)}; $$而 Allen-Cahn (AC) 方程则为:
$$ \frac{\partial \eta_p}{\partial t} = -L_{pq}\frac{\delta F}{\delta\eta_q\left( r,t \right)}. $$两个方程里的 $F$ 是能量泛函,$M$ 和 $L$ 是两个方程的动力系数。
在做相场模拟的时候,在构建好相场理论(能量描述,演化方程)之后,就需要设置求解相关的内容。首先需要对初始结构建模,换句话说也就是初值;然后需要有合适的边界条件来让场正常演化。一切准备就绪之后,就是写程序,模拟并输出结果了。
那么,在这个系列中,我们要模拟什么好呢?要说起相场模拟,最早应该追溯到 Cahn 用它来模拟二元合金的调幅分解了,而这么经典的模拟,模型却意外地简单。在 S. Bulent Biner 所著的 Programming Phase-Field Modeling 中,它用到的第一个案例就是二元合金的调幅分解了。这本书中用的程序语言是 Matlab,一个我不太喜欢的语言(因为我不会),不过作为计算参考已经足够了。
系列介绍和本文计划
这个系列计划是会把主流编程语言都试一遍,再试试有些非主流的语言和方法,不管笔者到底会不会这门语言。如果会,那就写;如果不会,那就学了再写。本文打算用笔者最熟悉的 C++ 和 Python 开始,再用程序老资历之一 C 和新生代最火的 “编程原神” Rust 来实现一下这两个模拟。代码会贴在每一段的后面,在实现的前面会简单介绍一下这门语言,然后在实现之后给出结果和可能有的评论。后续的文章可能会考虑换一个模拟案例,大概就是仿照 Programming Phase-Field Modeling 这本书的案例了。
另外,在实现这些计算的过程中,我们尽可能尝试突出这门语言的特点。这意味着某种语言的实现可能有若干个版本。
调幅分解的相场理论
其实在 相场模拟学习笔记 IV 里就已经对调幅分解做了些介绍,但是为了内容的完整性,我们还是贴在这里。
调幅分解简介
调幅分解是在自由能-成分曲线呈现双势阱状态时会体系可能会发生的一种相变,其主要特点为没有相变的型核过程,且体系具有双势阱型的自由能。它的自由能-成分曲线图和相图如图所示:
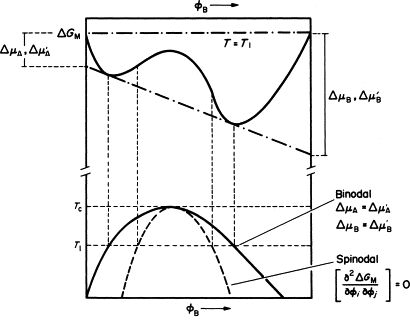
根据热力学理论,若一个过程能让体系自由能下降,那么这个过程就很可能会自发进行。当成分位于势阱中间的位置(比较高且在两个曲线拐点以内)时,由于成分小幅度波动会让整个体系自发地发生自由能下降,进而影响周围的区域带动相分离。
相场模型
我们自然是采用 CH 方程来演化这个体系,重要的是自由能的构成。为了模仿这样的双势阱,我们用一个很简单的函数来表示这样的自由能曲线:
$$f_{\mathrm{bulk}} = Ac^2(1-c)^2,$$其中 $A$ 是用来控制曲线高度的参数。而有了体能之后,我们需要有界面能来让体系形成扩散界面。我们使用最经典的梯度能模型:
$$f_{\mathrm{bound}} = \frac{1}{2} \kappa |\nabla c|^2,$$这样的梯度能只会在某个点处上下左右成分不同的情况下才会有值,且差别越大这个值就越大,从而能成功避免界面太尖锐(左边是 0 右边是 1 这样)。
经过一些(也许)不难的数学推导,我们很快得到我们要解的方程:
$$\frac{\partial c}{\partial t} = M \nabla^2\left( 2Ac(1-c)(1-2c)-\kappa\nabla^2c\right)$$参数设置
为了计算简单不出错,我们直接用书中的参数。模型参数中,$A = 1.0$,$M = 1.0$,$\kappa = 0.5$。建模方面,取初始浓度为 $c_0 = 0.4$, 并在每个点生成随机的浓度噪声,噪声最大值为 $\delta c = 0.005$。然后考虑离散步长,取 $\Delta t= 0.01$,$\Delta x= 1.0$。模拟域设为 $64\times 64$ 的正方形区域。边界条件设为周期性条件,即左边的点再向左走就取到最右边的值,上下同理。
C++ 的实现:
C++ 算是笔者做相场时第一个接触的语言了。用 C++ 做相场某种角度上是平衡了使用难度和运行效率的选择,吧?我们就从这个开始吧。
C++ 的简单介绍
C++ 是斯特劳普 (Bjarne Stroustrup) 教授于 1979 年在贝尔实验室设计开发的高级编程语言。它某种角度上是对 C 语言的扩充和发展,但是也不是完全兼容 C 语言的(漫长的发展历程中二者逐渐分道扬镳了)。C++ 的特点在于引入了 类 用来组织和管理数据,且在发展过程中人们发现 C++ 能够支持 模板元编程 来让某种处理逻辑能够处理不同的数据类型。相比起 C 语言十分接近硬件的特点,C++ 的工具库更多,也更适合构建复杂的应用程序,如今广泛应用在游戏,高性能计算等领域。不过,经过长时间的发展,C++ 的功能越来越丰富,但是语法也越来越复杂,入门门槛也变得很高。从 C++17 标准开始的所谓 现代 C++ 与这之前的 C++ 写法风格上有很大的区别,甚至有人会认为这已经是另一门语言了。
这里的实现会用一些现代 C++ 的特性以及很好用的新加入的标准库,比如一些用来生成随机数的,用来管理文件系统的标准库,不过这些代码应该也不会太难懂。笔者的环境是 Windows 10,最合理的选择自然是 MSVC,但是也会尝试保证代码能够正常运行在各个平台。
我们开始吧。
C++ 的一种实现
我们先做一些准备工作,然后就是设计算法并进行计算了。完整的代码会附在这一小节的最后。
计算准备
首先我们先把各种常数定义下来。我们把它们放在最前面,以便后面使用。这种做法有一些争议(在需要引入变量的时候再引入,而不是在程序最开始就定义),但是统一定义在前面的好处主要在于这些都是控制模型/模拟过程的常数,分散在程序内部不方便统一管理。
1constexpr int Nx = 64, Ny = 64, Nstep = 10000;
2constexpr float dx = 1.0f, dt = 0.01f;
3constexpr float M = 1.0f, A = 1.0f, kappa = 0.5f
4constexpr float dcon = 0.05f, con_init = 0.4f;
注意到这里我们用到了 constexpr,这是期望编译器进行编译期计算,不过在这儿效果约等于 const 就是了。另外,我们给浮点数的后面用 f 做后缀来告诉编译器它的确是一个 float 类型变量而不是从 double 变量强转过来的 float 类型。为什么用 float?答案很简单:我们的模拟不需要那么高的精度,变量短一点有利于计算效率。当然,这个程序里的所有浮点数部分都换成 double 也是不错的选择,反正这个计算挺快的。
随后我们借助 <random> 库中的 std::random_device 类来生成一个随机数种子,再用 std::uniform_real_distribution<float>() 模板类来生成从 $-0.005$ 到 $0.005$ 的随机浓度波动:
1std::random_device rd;
2std::uniform_real_distribution<float> dist(-dcon, dcon);
这个地方得到的类 dist 可以被当作一个函数,在后续通过接受 rd 这个随机数种子作为参数就能来生成一个在规定范围内的随机值。
最后一步就是准备好我们的网格了。我们用二重 vector 来承载整个浓度网格 con_mesh。这里因为我们知道整个模拟区域内平均浓度为 $0.4$,因此我们直接在 $Nx\times Ny$ 这么大的整个区域上的每个点都填上 $0.4$:
1vector<vector<float>> con_mesh(64, vector<float>(64, 0.4));
这里我们用到了匿名临时对象 vector<float>(64,0.4),这也是调用了类的构造函数 vector<Type>(Num,Value)。随后我们遍历整个网格,给网格内的每个点都加上浓度的微小变动:
1for (auto &row : con_mesh) {
2 for (auto &point : row) {
3 point += dist(rd);
4 }
5}
这里我们用到了迭代器循环:for (type value : container) 的语法能让具有迭代器的 container 被自动地从第一个值遍历到最后一个值。一般来讲这里的 type 用 auto 来让编译器自动推导类型,另外这里使用 auto & 来按引用取容器中的值,以保证值可以正确更新到网格内,否则只会把值更新在循环的临时变量里,不会正确地更新进容器内。由于我们的随机数一开始就是从 $-0.005$ 到 $0.005$ 的,所以这里直接放心加上去就可以了。
至此,我们就做好了模型参数确定以及几何建模。下面就是迭代计算的算法了。
迭代计算
在向前差分法中,我们的每一次计算都是针对于某一时间步进行的。为实现时间不断前进,我们自然需要用一个大的时间循环,而在每个时间循环内,我们都认为这里的事情是瞬间同时发生的。我们的时间循环写为:
1for (int istep = 0; istep < Nstep + 1; istep++){
2 // ...
3}
这里我们给总时间步数加了 $1$,因为我们认为第 $0$ 步是初始结构,还没有开始演化。或者说这也是为了后续方便进行文件输出(每 $100$ 步输出一次,加 $1$ 就能输出最后一步了)。
下来自然是考虑实现计算核心的部分了。观察表达式,可以发现计算过程中有不涉及网格的部分(体能计算),也有涉及网格的部分(Laplacian)。由于函数是逐点定义的,不涉及网格的计算中,对某点的计算只需要该点的值即可;涉及网格的计算则需要获取网格点周边相邻点的信息。体能计算可以被写为一个函数:
1float df_bulk_dc(float con, float A) {
2 return 2 * A * con * (1 - con) * (1 - 2 * con);
3}
上面的总求解式中共出现了两次 Laplacian 计算,而对 Laplacian 的计算则需要在每个点周围的 $3\times 3$ 的网格里计算出中心点的 Laplacian 值。我们先不考虑取周围点的操作,将它们抽象为 4 个数值,算法则很简单了:
1float laplacian(float v_c, float v_l, float v_r, float v_u, float v_d, float dx) {
2 return (v_l + v_r + v_u + v_d - 4 * v_c) / (dx * dx);
3}
最后,为了能放心大胆地做计算,我们先处理边界数值,然后对中心点做计算即可。而对于重复出现的网格依赖操作,我们干脆直接把带有边界条件的网格遍历过程打包成一个函数:
1vector<vector<float>> mesh_periodic(
2 vector<vector<float>> mesh, int Nx, int Ny, float dx,
3 std::function<float(float, float, float, float, float, float)> kernel_func) {
4
5 float v_l, v_r, v_u, v_d, v_c;
6 vector<vector<float>> next_mesh(Nx, vector<float>(Ny));
7 for (int j = 0; j < Nx; j++) {
8 for (int i = 0; i < Nx; i++) {
9
10 v_c = mesh.at(j).at(i);
11 // x-minus
12 if (i == 0) {
13 v_l = mesh.at(j).at(Nx - 1);
14 } else {
15 v_l = mesh.at(j).at(i - 1);
16 }
17 // x-plus
18 if (i == Nx - 1) {
19 v_r = mesh.at(j).at(0);
20 } else {
21 v_l = mesh.at(j).at(i + 1);
22 }
23 // y-minus
24 if (j == 0) {
25 v_d = mesh.at(Ny - 1).at(i);
26 } else {
27 v_l = mesh.at(j - 1).at(i);
28 }
29 // y-plus
30 if (j == 0) {
31 v_u = mesh.at(0).at(i);
32 } else {
33 v_l = mesh.at(j + 1).at(i);
34 }
35
36 next_mesh.at(i).at(j) = kernel_func(v_l, v_r, v_u, v_d, v_c, dx);
37 }
38 }
39 return next_mesh;
40}
我们聊一聊这个函数。首先,它接受某个二维网格作为待计算的网格,其次传入几何信息方便遍历以及网格依赖计算。最后,对于要计算的具体内容我们抽象为了一个函数对象 kernel_func。这个函数对象代表了这样一类函数:它接受 6 个 float 参数后返回一个 float 参数。函数对象的优势在于,我们可以暂时不用关心具体计算过程,把目光聚焦在怎么为这个计算准备合适的环境。
随后,我们考虑周期性边界条件:当中心点位于边界上时,比如 $x$ 轴方向的左边界 (x = 0),此时这个点的右侧是能自然取到值的,但左侧则没有结果。为了让右侧能取到值,我们要求此时取左侧值则取到求解区域的右边界值。这需要我们对每一个遍历到的位置的 i 和 j 都做两次判断(共4次),而为了做这样的边界处理,我们要把每个取到的值都存在临时变量内。
最后,由于我们的计算核心逻辑都被抽象到了 kernel_func 中,我们只需要再取一个同样大小的网格,把结果更新到里面就好。这里我们采用函数返回网格的方式,我们也可以让函数把值更新到以引用方式传入的参数里。
在准备好计算的逻辑组件后,我们需要将这些组件进行组合。由于要计算两次 Laplacian,我们就把上面带边界条件的遍历逻辑来应用两次,第一次得到的网格即为 $\frac{\delta F}{\delta c} = 2Ac(1-c)(1-2c)-\kappa\nabla^2c$ 的结果,这里要把 laplacian 和 df_bulk_dc 等通过合适的组合后放入上面 mesh_periodic 函数中的 kernel_func 里,我们用一下 Lambda 表达式来组成匿名的临时函数:
1vector<vector<float>> df_dc = mesh_periodic(
2 con_mesh, Nx, Ny, dx,
3 [kappa, A](float v_1, float v_2, float v_3, float v_4, float v_5, float v_6) {
4 return df_bulk_dc(v_1, A) - kappa * laplacian(v_1, v_2, v_3, v_4, v_5, v_6);
5 });
我们解释一下最后一个作为函数对象的参数。Lambda 表达式是在 C++ 11 中加入的匿名函数,是现代编程语言的一个常见的语法特性。它通过前面的 [] 来捕捉上文的和函数有关但不作为参数传入的变量,通过 () 来确定函数的参数列表,最后在 {} 中定义函数。由于我们的函数对象要求以 6 个 float 变量作为输入,因此我们的 Lambda 表达式的参数列表要有 6 个 float;由于我们的结果要返回一个 float,我们在函数体内返回时也如此返回。注意到我们的计算中需要 kappa 和 A 两个常量参与计算,但它们又不能进入参数列表中(虽然参数列表用了不知所云的 v_*,但它们的实际意义则是前 5 个参数为中,左,右,上,下的网格值,最后一个参数为网格宽度。因此,我们把它们作为函数应该知道的上下文,通过 [] 列表告诉它。
在进行完这个迭代后,我们需要进一步进行迭代,再次求 $\frac{\delta F}{\delta c}$ 网格的 Laplacian 得到浓度的变化量:
1vector<vector<float>> dc = mesh_periodic(
2 df_dc, Nx, Ny, dx,
3 laplacian);
这样我们就得到了浓度对时间的导数了。最后一步就是把浓度变化量乘以浓度的迁移率 $M$ 再更新浓度场:
1for (int j = 0; j < Ny; j++) {
2 for (int i = 0; i < Nx; i++) {
3 con_mesh.at(j).at(i) += dt * M * dc.at(j).at(i);
4 }
5}
这样,我们就实现了一个时间步内的演化,直接把组合好的逻辑扔进时间步循环里就已经可以进行计算了。
结果输出
但是我们的计算结果应该以某种方式输出出来。这里我们借助 C++17 引入的 filesystem 工具库来把网格结果以既定格式(VTK)输出到文件中,最后就可以用 Paraview 来可视化了。我们把输出逻辑打包为了一个函数:
1void write_vtk(vector<vector<float>> mesh, string file_path, int time_step, float dx) {
2 fs::create_directory(file_path);
3 fs::path f_name{"step_" + std::to_string(time_step) + ".vtk"};
4 f_name = file_path / f_name;
5
6 ofstream ofs{f_name};
7 int Nx = static_cast<int>(mesh.size()), Ny = static_cast<int>(mesh.at(0).size());
8
9 ofs << "# vtk DataFile Version 3.0\n";
10 ofs << f_name.string() << endl;
11 ofs << "ASCII\n";
12
13 ofs << "DATASET STRUCTURED_GRID\n";
14 ofs << "DIMENSIONS " << Nx << " " << Ny << " " << 1 << "\n";
15 ofs << "POINTS " << Nx * Ny * 1 << " float\n";
16
17 for (int j = 0; j < Ny; j++) {
18 for (int i = 0; i < Nx; i++) {
19 ofs << (float)i * dx << " " << (float)j * dx << " " << 1 << endl;
20 }
21 }
22 ofs << "POINT_DATA " << Nx * Ny * 1 << endl;
23
24 ofs << "SCALARS " << "CON " << "float 1\n";
25 ofs << "LOOKUP_TABLE default\n";
26 for (int j = 0; j < Ny; j++) {
27 for (int i = 0; i < Nx; i++) {
28 ofs << mesh.at(j).at(i) << endl;
29 }
30 }
31
32 ofs.close();
33}
这个函数首先接受要输出的网格作为参数;其次为了把文件输出到合适的位置并区分不同时间步,我们将文件路径和时间步作为参数输入函数;最后为了准确描述网格的几何情况,我们将网格步长输入。
在函数内,我们先检测对应的文件夹路径是否存在。std::filesystem::create_directory 提供了很方便的方法,当文件夹存在则什么都不做,当文件夹不存在就创建个空的文件夹。之后我们以合适的规则为文件进行命名,得到文件名的完整路径后使用 <fstream> 提供的 std::ofstream 对象将内存中的值输出到文件里。这个对象可以以文件路径进行初始化,并且可以像平时 std::cout 把文字输出在屏幕那样的流式操作把文件内容按行输出出来。随后我们从网格本身的信息反推出 Nx 和 Ny 的大小。由于 vector.size() 方法返回的值类型为大小安全的 size_t,而我们清楚我们用不到这么大,且整个程序都使用了 int 作为整型,所以这里 需要进行一次数据类型转换。static_cast 是 C++ 引入的静态类型转换方式,方便我们安全地进行数据类型转换。
接下来是 VTK 文件的格式规范。首先确定 VTK 的格式版本,再将文件自身的文件名输入第二行,最后规定文件的编码,完成文件头的定义。
然后我们还需要规定文件描述的网格类型。由于我们采用的是横平竖直的,可以用笛卡尔坐标确定每个点位置的网格,这恰好是结构化网格最适合描述的。因此我们便声明 DATASET STRUCTURED_GRID;对于结构化网格,需要确定网格的大小和每个格点的位置(三维坐标)。因此我们先规定 DIMENSION NX NY NZ 描述网格点的数量,再显式提供网格点的总数和坐标的数据类型(这里是 float),最后把网格的坐标依次列出。
最后,我们就需要描述每个点上的值了。VTK 格式允许我们添加多个数据集,让每个点上有多个性质。不过在这个案例里,我们只需要描述浓度一个信息就可以了。每个数据集以 POINT_DATA 和数据量开头,描述数据类型(标量或矢量),数据集名和数据的存储类型(这里依旧是 float),再定义查表方式 LOOKUP_TABLE(这里 default 即可),最后就把每个点的值依次列出就好了。
在向一个文件内输出所有结果后,最好显式调用 ofstream.close() 来关掉这个文件流。当然不管也可以,由于 C++ RAII 的特性,满足 RAII 的类在离开作用域的时候会自动调用析构函数销毁自身。
有这个文件输出函数之后,我们只需要在时间循环的过程中,选择合适的时间点调用这个函数进行结果输出即可。一个好方法是 if(istep %100 == 0){},这个条件能自动地在每 $100$ 步的时候输出一次结果。
另外我们还可以对计算过程进行计时。借用 C++17 提供的 <chrono> 标准库,我们可以方便地用 std::chrono::high_resolution_clock::now() 来获取程序运行这一语句时的时间点,再用 std::chrono::high_resolution_clock::duration_cast 来把两个时间点之差转化为合适的时间单位。我们有如下实现:
1int main(int, char**){
2 using hrc = std::chrono::high_resolution_clock;
3 namespace chrono = std::chrono;
4 const auto timepoint_start = hrc::now();
5
6 // other things ...
7
8 const auto timepoint_stop = hrc::now();
9 const auto time_cost = chrono::duration_cast<chrono::milliseconds>(timepoint_stop - timepoint_start);
10 cout << "Calculation time cost: " << static_cast<double>(time_cost.count()) / 1000.0 << "seconds." << endl;
11}
上面我们用 using 声明了 std::chrono::high_resolution_clock 的类型别名,再用 namespace 为 std::chrono 声明了命名空间的别名,方便我们的手和眼睛。另外我们这里有一个小巧思:把时间转为用毫秒计算的格式,再转化为 double 类型后除以 $1000$ 来得到有 3 位小数点的秒数。直接转为 chrono::seconds 的话只会展示整秒数,而用这里的手法可以获得稍微更精确的时间。
完整代码
最后,在补好所有的头文件并合理使用一些 std 命名空间内的名称后,我们得到了一个能够被三大主流编译器(GCC,Clang/LLVM,MSVC)编译运行的一份相场代码。它的运行结果和 相场模拟学习笔记 IV 的结果大同小异,这里就不贴出来了。你可以点击 这个链接 来浏览这个文件。
C++ 的另一个版本
这次的这个版本相比于之前在笔记里写的而言,最突出的特点可能就在于使用了函数对象。函数对象的存在允许我们彻底地将一部分逻辑(方便地)抽离出来,从而逐步分层地实现计算逻辑。虽然不用函数对象也可以做到类似的事(via 函数指针),但是函数对象的方式更加简单,快速且安全。得益于模板类以及 C++ 标准库实现遵循的 RAII 与 Zero-overhead 原则,我们有理由相信编译器会帮我们处理好代码底下的小九九,让运行过程依旧足够高效,且在对象离开作用域时被 RAII 机制自动回收,避免到处指针造成的内存泄漏。
不过,这个 C++ 的实现版本依旧没有体现 C++ 的面向对象特性。总体上看,我们也就只是用了一些已经打包好的工具类而已,并没有自己把数据组织起来并赋予操作数据的方法。然而,相场法天然的网格特性很适合用类进行打包。那么我们的下一个版本就可以考虑加上这个特性,看看用了类的版本会有什么不同。
设计数据结构
相场法最核心的数据,毫无疑问就是用来参与计算的网格了。我们可以考虑这样一个用于计算的网格都需要有哪些属性:
- 网格数据
- 网格大小
- 网格步长
- 边界条件
其中,第二个也许可以纳入网格数据内,毕竟大小是很快可以从实际存储数据的结构中用类似 .size() 的方法获得的,不过我们列在这里也是为了方便取用。如此,我们可以立刻得到这样的数据结构:
1template <typename T, typename = std::enable_if_t<std::is_floating_point_v<T>>>
2class Mesh {
3private:
4 vector<vector<T>> mesh_data;
5 size_t Nx;
6 size_t Ny;
7 T dx, dy;
8 BoundFuncs<T> boundary_condition;
9
10public:
11 Mesh() = delete;
12
13 Mesh(size_t _Nx, size_t _Ny, T _dx, T _dy, BoundFuncs<T> _bound_funcs,
14 T _init_value = T())
15 : Nx(_Nx), Ny(_Ny), dx(_dx), dy(_dy), boundary_condition(_bound_funcs) {
16 mesh_data = vector<vector<T>>(_Ny, vector<T>(_Nx, _init_value));
17 }
18
19 Mesh(size_t _Nx, size_t _Ny, T _dx, T _dy, T _init_value = T())
20 : Mesh(_Nx, _Ny, _dx, _dy, BoundFuncs<T>(), _init_value) {}
21
22 Mesh(size_t _Nx, size_t _Ny, T _d_mesh, T _init_value = T())
23 : Mesh(_Nx, _Ny, _d_mesh, _d_mesh, BoundFuncs<T>(), _init_value) {}
24
25 Mesh(size_t _N_mesh, T _d_mesh, T _init_value = T())
26 : Mesh(_N_mesh, _N_mesh, _d_mesh, _d_mesh, BoundFuncs<T>(), _init_value) {}
27
28 Mesh(T _dx, T _dy, BoundFuncs<T> _bounds, vector<vector<T>> &_data) : mesh_data(_data) {
29 Ny = mesh_data.size();
30 Nx = mesh_data.at(0).size();
31 dx = _dx;
32 dy = _dy;
33 boundary_condition = _bounds;
34 }
35
36 const size_t get_dim_x() const {
37 return Nx;
38 }
39
40 const size_t get_dim_y() const {
41 return Ny;
42 }
43
44 const T &get(size_t _x, size_t _y) const {
45 return mesh_data.at(_y).at(_x);
46 }
47
48
49 vector<vector<T>> &get_data() const {
50 return mesh_data;
51 }
52
53 // ...
54};
可以注意到这里我们使用了 template 关键字,这是所谓的 模板,可以用来接受一些数据类型然后将类/函数以对应的数据类型实现。我们使用它的主要原因是希望能让这份代码适用于不同的浮点数精度。在不追求精度的时候可以使用 float 来实现这个模板,而在需要时则可以使用 double。由于我们只希望这类浮点数作为备选的数据类型,在模板类型名称的后面使用了 typename = std::enable_if_t<std::is_floating_point_v<T>> 的写法来保证它一定是一个可计算的浮点数。
这个类主要数据包含:网格点数值,网格大小,网格步长以及网格的边界条件。我们设计了若干种方式来初始化一个网格,另外这里对边界的组织方式应该是这个版本最大的特点。考虑到我们的边界实际上只是规定当下标越界时,应该如何取值以继续计算,于是我们可以把这个任务抽象为给每个位置赋予一个函数,当下标越界时就调用该函数获得对应的值。我们稍后会提到它。
另外由于我们把所有的数据都保护了起来,就还必须有选择地向外暴露数据。在实际计算中,我们发现经常需要取用某一点的值,或者需要将整个数据网格都取出来方便遍历;同时经常需要获得网格的长与宽。这样的需求让我们设计了四个对外公开的函数,功能也很简单,就是把值告诉外界。
计算逻辑
接下来我们需要添加计算逻辑。很自然地,我们可以想到把之前的 mesh_periodic 挪过来,在类内进行操作。我们得到的新的计算函数如下:
1Mesh iterate_mesh(std::function<float(float, float, float, float, float, float)> kernel_func) {
2 float v_l, v_r, v_u, v_d, v_c;
3 vector<vector<float>> next_mesh_data(Nx, vector<float>(Ny));
4
5 for (int j = 0; j < Nx; j++) {
6 for (int i = 0; i < Nx; i++) {
7 v_c = mesh_data.at(j).at(i);
8 // x-minus
9 if (i == 0) {
10 v_l = boundary_condition.x_m->bound_x_m(*this, j);
11 } else {
12 v_l = mesh_data.at(j).at(i - 1);
13 }
14 // x-plus
15 if (i == Nx - 1) {
16 v_r = boundary_condition.x_p->bound_x_p(*this, j);
17 } else {
18 v_r = mesh_data.at(j).at(i + 1);
19 }
20 // y-minus
21 if (j == 0) {
22 v_d = boundary_condition.y_m->bound_y_m(*this, i);
23 } else {
24 v_d = mesh_data.at(j - 1).at(i);
25 }
26 // y-plus
27 if (j == Ny - 1) {
28 v_u = boundary_condition.y_p->bound_y_p(*this, i);
29 } else {
30 v_u = mesh_data.at(j + 1).at(i);
31 }
32
33 next_mesh_data.at(j).at(i) = kernel_func(v_c, v_l, v_r, v_u, v_d, dx);
34 }
35 }
36 Mesh next_mesh(dx, dy, boundary_condition, next_mesh_data);
37 return next_mesh;
38}
可以看到,因为很多数据都被类自然地涵盖了,我们不需要再把数据通过函数参数传入。另外,由于我们考虑使用不同的边界条件,这里统一使用 boundary_condition.{bd}->{bd-value-func} 的模式来调用函数实现边界计算。这个函数因为会生成别的网格,因此我们还需要把计算得到的结果重新包装为 Mesh 后再传出。
除了通过网格自身计算得到新的网格之外,我们还需要两个网格交互得到第三个网格,以及一个网格用另一个网格来更新自身。由于这个案例中我们主要是需要让浓度场计算后用新网格迭代自身,我们实现了后者。再考虑到有时我们需要根据某种标量来更新自身,我们这里也引入了一个重载的实现。结果如下:
1void update(const Mesh &_mesh) {
2 for (size_t j = 0; j < Ny; j++) {
3 for (size_t i = 0; i < Nx; i++) {
4 mesh_data.at(j).at(i) += _mesh.get(i, j);
5 }
6 }
7}
8void update(std::function<float()> kernel_func) {
9 for (auto &row : mesh_data) {
10 for (auto &point : row) {
11 point += kernel_func();
12 }
13 }
14}
最后,我们希望网格能够将结果输出到文件里,因此我们把之前的 write_vtk 稍作改造:
1void write_vtk(string file_path, size_t time_step) {
2 const auto &mesh = mesh_data;
3 fs::create_directory(file_path);
4 fs::path f_name{"step_" + std::to_string(time_step) + ".vtk"};
5 f_name = file_path / f_name;
6 ofstream ofs{f_name};
7 ofs << "# vtk DataFile Version 3.0\n";
8 ofs << f_name.string() << endl;
9 ofs << "ASCII\n";
10 ofs << "DATASET STRUCTURED_GRID\n";
11 ofs << "DIMENSIONS " << Nx << " " << Ny << " " << 1 << "\n";
12 ofs << "POINTS " << Nx * Ny * 1 << " float\n";
13 for (size_t j = 0; j < Ny; j++) {
14 for (size_t i = 0; i < Nx; i++) {
15 ofs << (float)i * dx << " " << (float)j * dy << " " << 1 << endl;
16 }
17 }
18 ofs << "POINT_DATA " << Nx * Ny * 1 << endl;
19 ofs << "SCALARS " << "CON " << "float 1\n";
20 ofs << "LOOKUP_TABLE default\n";
21 for (size_t j = 0; j < Ny; j++) {
22 for (size_t i = 0; i < Nx; i++) {
23 ofs << mesh.at(j).at(i) << endl;
24 }
25 }
26 ofs.close();
27}
至此我们完成了主网格的设计。
更灵活的边界条件
接下来我们就需要设计如何实现多边界条件。因为我们可能会遇到多种多样的边界条件,而在二维模拟域中我们只有 4 条边界。因此,我们可以用一个类来统筹管理这四条边界,即为在前面网格中出现的 BoundFuncs<T>,而这四条边界究竟是什么样的,我们则需要根据实际需求在主函数中去告诉它。为了实现这一点,我们采用抽象类 AbstractBounds<T> 和可以被子类重载的虚函数 bound_x_m。
1template <typename T, typename = std::enable_if_t<std::is_floating_point_v<T>>>
2struct AbstractBounds {
3 virtual ~AbstractBounds() = default;
4 virtual T bound_x_m(const Mesh<T> &mesh, size_t y) const = 0;
5 virtual T bound_x_p(const Mesh<T> &mesh, size_t y) const = 0;
6 virtual T bound_y_m(const Mesh<T> &mesh, size_t x) const = 0;
7 virtual T bound_y_p(const Mesh<T> &mesh, size_t x) const = 0;
8};
9
10template <typename T, typename = std::enable_if_t<std::is_floating_point_v<T>>>
11struct BoundFuncs {
12 using BoundPtr = std::shared_ptr<const AbstractBounds<T>>;
13
14 BoundPtr x_m;
15 BoundPtr x_p;
16 BoundPtr y_m;
17 BoundPtr y_p;
18
19 // default: periodic boundary
20
21 BoundFuncs(BoundPtr _x_m, BoundPtr _x_p, BoundPtr _y_m, BoundPtr _y_p)
22 : x_m(std::move(_x_m)), x_p(std::move(_x_p)), y_m(std::move(_y_m)), y_p(std::move(_y_p)) {
23 if (!x_m || !x_p || !y_m || !y_p) {
24 throw std::invalid_argument("Boundary condition pointers must not be null");
25 }
26 }
27};
这里 bound_x_m 等函数默认接收 const Mesh<T>$ 和 size_t 作为参数,因为这些内容在涉及到边界计算时是极为常见的,我们就不单独将二者作为子类的成员提出后单独赋值再计算,而是采用这种方式。在创建边界条件时,我们需要用 std::make_shared 来承接抽象类,且得到的 shared_ptr 可以被复制和共享。接下来是设计对应的边界条件,这里我们设计了两种:周期性边界条件与固定边界条件。实现如下:
1template <typename T, typename = std::enable_if_t<std::is_floating_point_v<T>>>
2struct PeriodicBound : AbstractBounds<T> {
3 T bound_x_m(const Mesh<T> &mesh, size_t y) const override {
4 return mesh.get(mesh.get_dim_x() - 1, y);
5 }
6 T bound_x_p(const Mesh<T> &mesh, size_t y) const override {
7 return mesh.get(0, y);
8 }
9 T bound_y_m(const Mesh<T> &mesh, size_t x) const override {
10 return mesh.get(x, mesh.get_dim_y() - 1);
11 }
12 T bound_y_p(const Mesh<T> &mesh, size_t x) const override {
13 return mesh.get(x, 0);
14 }
15};
16template <typename T, typename = std::enable_if_t<std::is_floating_point_v<T>>>
17struct FixedBound : AbstractBounds<T> {
18 T fixed_val;
19 FixedBound(T _val) : fixed_val(_val) {}
20 T bound_x_m(const Mesh<T> &, size_t) const override {
21 return fixed_val;
22 }
23 T bound_x_p(const Mesh<T> &, size_t) const override {
24 return fixed_val;
25 }
26 T bound_y_m(const Mesh<T> &, size_t) const override {
27 return fixed_val;
28 }
29 T bound_y_p(const Mesh<T> &, size_t) const override {
30 return fixed_val;
31 }
32};
如果需要别的边界条件,且新的边界条件需要依赖更复杂的参数时,就可以创建新的抽象类实现,将参数作为子类的成员加以描述。实际的代码中我们还让 BoundFucs<T> 默认取周期性边界条件,方便平时使用(很多模拟都偏爱周期条件)。
有了上面重新整理的类,再加上之前的函数组件,我们就可以开始在 main() 函数组装整个计算逻辑了。
主函数
最后我们看一下 main() 函数的写法:
1int main(int, char **) {
2
3 const auto timepoint_start = hrc::now();
4
5 // Parameters ...
6
7 auto dF_dc = [A, kappa](float v_1, float v_2, float v_3, float v_4, float v_5, float v_6) {
8 return df_bulk_dc(v_1, A) - kappa * laplacian(v_1, v_2, v_3, v_4, v_5, v_6);
9 };
10 auto dc_dt = [M, dt](float v_1, float v_2, float v_3, float v_4, float v_5, float v_6) {
11 return dt * M * laplacian(v_1, v_2, v_3, v_4, v_5, v_6);
12 };
13 auto add_noise = [dcon]() {
14 std::random_device rd;
15 std::uniform_real_distribution<float> dist(-dcon, dcon);
16 return dist(rd);
17 };
18
19 using PB = PeriodicBound<float>;
20 BoundFuncs<float> boundary(
21 std::make_shared<PB>(),
22 std::make_shared<PB>(),
23 std::make_shared<PB>(),
24 std::make_shared<PB>());
25 Mesh<float> con_mesh(Nx, Ny, dx, dx, boundary, con_init);
26
27 con_mesh.update(add_noise);
28
29 cout << "Initialize complete" << endl;
30
31 for (size_t istep = 0; istep < Nstep + 1; istep++) {
32
33 auto df_dc = con_mesh.iterate_mesh(dF_dc);
34 auto dc = df_dc.iterate_mesh(dc_dt);
35 con_mesh.update(dc);
36
37 // result output
38 if (istep % 100 == 0) {
39 con_mesh.write_vtk("./output", istep);
40 cout << "Result " << istep << " outputed" << endl;
41 }
42 }
43
44 const auto timepoint_stop = hrc::now();
45 const auto time_cost = duration_cast<milliseconds>(timepoint_stop - timepoint_start);
46 cout << "Calculation time cost: " << static_cast<double>(time_cost.count()) / 1000.0 << "seconds." << endl;
47}
可以看到这份代码结构更加清晰,main() 函数内完全被划分为三大块:模拟准备,时间循环 和 后处理。而且整体逻辑更清晰一些,完全围绕 con_mesh 以及其衍生网格结构发展,得到的结果也可以快速迭代回自身。借助 Mesh.update() 函数,我们可以让添加噪音的过程变成一次数值更新赋予网格中的每个点。而时间循环中真正实现了三步走:计算两个依赖网格的量,然后将结果迭代回原网格。
这份代码同样上传到了这个博客里,你可以通过点击 这里 来浏览并下载这份源代码。
总结与后记
其实一开始我是希望快速完成 C++ 以及 Python 的实现,然后快进至更有趣的一些语言的。然而在我开始动笔写 C++ 的实现时,我发现缺了很多东西:没有对相场的介绍,没有对模拟的介绍,也没有对语言的介绍。再将它们补充后,我又在想,C++ 的实现能不能再多一些有趣的,我之前没有试过的实现方式?这就成为了第一个案例。而在那之后,我发现 C++ 身为一个支持多范式编程(面向过程,面向对象,函数式,元编程等等)的语言,我竟然只草草地只是加了一些现代 C++ 的工具类之后就用面向过程的方式写完了。于是便有了第二个实现的结果。
平心而论,第二种实现因为涉及到的虚函数,抽象类这些平时不怎么用的东西,我也是边学边写的,而且也因为如此,第二份代码的性能略低于第一份,有很大的 Over-engineering 的嫌疑。不过感谢 RAII,从计时器的结果来看二者相差并不大,顶多只有 1s 不到的差距。再者,这里的实现并没有过多地考虑计算效率,(也许)更多地希望代码简洁易懂,所以这儿并没有采用一些激进的计算优化措施,比如用更高效的 C++ 计算库,或者使用单 vector 来帮助编译器做向量化之类的。不过我们会在别的语言中尝试这些。
这篇文章作为本系列的头阵,也许我们后续也会采用类似的方式来记录我是如何用别的语言实现这个模拟(或者其他模拟)的。如果这篇博客让您对相场法有了兴趣,愿意将代码在自己的机器上运行,并观察一下别的边界条件下的演化结果,那么这将是我莫大的荣幸。而若这篇博客的内容有什么错漏,也请海涵并在评论区指出,众多编程语言中我也就熟一点 C++,而且如您所见也写的不怎么好。若您对文章的内容有问题,意见或建议,也欢迎评论区交流~!
那么,感谢您能看到这里,祝您生活愉快,happy coding!